Develop your website right – 1
January 20, 2018 • Glenn Murray

Search engine bots don’t use websites the way you and I do. They need your site to be designed and built in a particular way. If you don’t do it right, you can severely hamper your search engine presence.
DEVELOPMENT CHECKLIST
There are quite a few web development dos and don’ts to remember. And it’d be too long to cover all of them in just one single post, so I split it into 2 posts. This one is about what you should do, and here is what you should do sparingly or not to do at all when developing a website.
Here’s a checklist that’ll make it all a little easier to grapple with. You’ll find further detail on each of these items below.
DO
- Choose the right web host
- Use HTML text copy, links & breadcrumb trails
- Position your content toward the top of your HTML code
- Create lots of content and regularly update your site
- Optimize Your HTML Meta-Tags
- Use image captions
- Cluster pages around keywords
- Add your name, address & phone number to every page if local customers are important to you
- Optimize your internal links
- Add Titles to internal links
- Use structured data if you deal with products, recipes, reviews, events or software apps
- Link to related sites
- Check for broken links
- Add a sitemap page
- Create a Google sitemap
- Use permanent 301 redirects for changed URLs
- Create a custom 404 error handling page
- Create a robots.txt file
- Use subfolders or subdomains – they’re both OK
- Consider making dynamic URLs static
CHOOSE THE RIGHT WEB HOST
Google shows different search results to different people, depending on where they’re searching from. This is particularly true of shopping-type searches for goods that are likely to be purchased in person (as opposed to online). For example, if you Google “bank” in the US, you’ll probably see Bank of America at number 1, whereas if you Google “bank” in Australia, you’ll probably see The Commonwealth Bank.
When deciding what sites to display, Google considers where each is hosted. It assumes that Americans will want to see American banks, and that American banks probably host their websites with American web hosts.
Put simply, if you’re after visitors from a particular country, choose a web host with servers in that country. And if you’re after visitors from a particular city, choose a web host with servers in that city.
USE HTML TEXT COPY, LINKS & BREADCRUMB TRAILS… AND ANYTHING ELSE IMPORTANT
Obviously, your copy, links and breadcrumb trails are critical to your visitor. They explain your offering, and help the visitor navigate and stay oriented. So the search engines will want to crawl these elements in order to figure out what your site’s about.
As a rule of thumb, search engines have trouble reading anything that’s not straight HTML. They can sometimes make some sense of non-HTML, but they can always read HTML. So play it safe. Unless you have a really good reason to do otherwise, make sure that all important copy, all important links – including your main navigation – and all breadcrumb trails are straight HTML.
When you view the source code (right-click a web page and select View Source), HTML text should look something like this:
<h1>Cheap second hand computers</h1> <p>Did you know that most second hand computers are retired because of their software, not because of their hardware?</p>
That’s a level one heading followed by a paragraph. Simple stuff – just how the search engines like it.
Here’s how a typical HTML link looks in the source code:
<p>Most computers slow down because they’re overloaded with <a href=”http://www.cheapsecondhandcomputers.com/ unhealthysoftware.html”>poorly maintained software</a>. It’s generally got nothing to do with the hardware.</p>
The bold bit’s the link.
And here’s how a typical HTML breadcrumb trail looks in the source code:
<p>You are here: <span>Company</span> <span>/</span> <a href="contact.htm" class="active">About Us</a></p>
If you saw the resultant copy on a web page, you’d be able to select it with your mouse – letter by letter. As a rule of thumb, if you can’t do that, the search engines can’t read it.

A web-page created from straight HTML – note the selected text
Of course, that’s a broad generalization, but it’s a good starting point. In practice, it’s a little more complicated than that. In practice, the search engines can read some stuff you can’t select, and they can’t read some stuff you can select. But there’s no point complicating matters like that unless you have a specific reason to do so.
TIP: You can also view the content without a stylesheet to see more-or-less what the search engines can read – assuming you’re using Firefox as your browser. Select View > Page Style > No Style.
For more information…
- on search friendly drop-down/rollover navigation menus, see ‘Avoid JavaScript’.
- on using Flash, see ‘Avoid Flash’.
- on using AJAX, see ‘Be careful with AJAX’.
- on using JavaScript, see ‘Avoid JavaScript’.
POSITION YOUR CONTENT TOWARD THE TOP OF YOUR HTML CODE
When the search engines look at your page, they don’t actually see the display version that you and I read. They read only the HTML behind the page. But they’re like us one key respect; they pay more attention to words at the top. They figure that’s is where the most important words will be.
What’s more, if there are two links on a page to the same target page, Google appears to only take the anchor text of the first into consideration when indexing. (For more information on this, see Rand Fishkin’s blog post, Results of Google Experimentation – Only the First Anchor Text Counts.)
So by placing your content toward the top of the page of code, you ensure that the keywords and links within are properly taken into account when your pages are indexed.
It’s quite common for web developers to code pages such that elements like images, sidebars, JavaScript (including Google Analytics code) and even footers appear above content in the code. (The page still displays correctly to visitors – just not to the search engines.) This can bury your content 1000 words or more down the page of code.
There’s absolutely no reason for this to happen. All of these elements can be coded after your content, especially if your developers are using Cascading Style Sheets (CSS), as they should.
Note that by placing your JavaScript toward the bottom of the page of code (e.g. before the </body> tag), you’ll make your page load faster for visitors. (They won’t have to sit and wait for the code to run before the page displays.) But there’s a trade- off. With your Google Analytics code loading late, it may not register all visits because people may leave quickly, closing the page before the Analytics code has finished running.
CREATE LOTS OF CONTENT AND REGULARLY UPDATE YOUR SITE
In Google’s eyes, it’s unlikely that a rarely updated site with minimal content is going to be helpful to visitors. It and the other search engines like to see lots of content, and they like to see it updated regularly.
Fortunately, that approach goes hand-in-hand with the most effective link building method, ‘link baiting’. Content is one of link baiting’s two core components (the other being social media).
Of course, I’m not talking any old rubbish, here. I’m talking useful, unique, high quality content.
That’s the only sort that works.
For more information…
- on link baiting, see ‘Link baiting’.
- on creating great content, see ‘Create great web content’.
OPTIMIZE YOUR HTML META- TAGS
Within the HTML code behind your page, there are things called ‘meta tags’. These are short notes within the header of the code that describe some aspects of your page to the search engines.
Although there is some debate over how important meta tags are to SEO, it’s generally agreed that they shouldn’t be ignored.
TITLE TAG
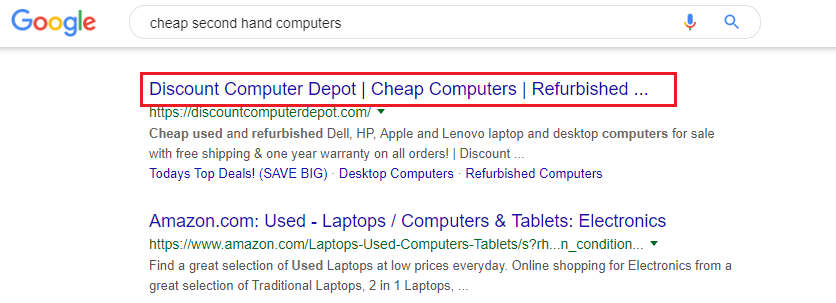
How the Title tag displays in Google
Because it functions as the headline of your SERPs listing, the search engines figure it’s likely you’ll make it something fairly relevant to the content of the target page, in order to get people to click through. As a result, they pay more attention to it than the other tags when indexing your site.
Try to use your keyword at least once in the Title, as close to the beginning of the tag as possible. But don’t use it again and again and again. That’s keyword stuffing, and you could be penalized.
You have 55 characters (including spaces) in which to write a compelling, keyword rich headline for your listing. (In most searches, Google displays only the first 50-60 characters. It cuts the end off anything longer than that.) The better your title, the more people will click on it. Be descriptive and accurate. In fact, why not consider the four criteria for an effective headline?
- Self Interest – Does it promise a benefit to the searcher?
- Quick, Easy Way – Does it offer one?
- News – Does it contain any?
- Curiosity – Does it sound interesting?
Also it can be a good idea to include your company name in the Title. Above all else, this helps develop brand recognition (especially when you rank on page 1), and lends credibility to your listing. E.g.:
World’s cheapest second-hand PCs GUARANTEED – CheapCom.com
And finally, it’s best not to use the same Title tag on every page. It’s supposed to be a headline, compelling searchers to click through to your page. If it’s generic enough to be suitable for every page, it’s not going to be particularly compelling.
HOW THE TITLE TAG SHOULD LOOK IN THE CODE
<title> World’s cheapest second-hand PCs GUARANTEED – CheapCom.com </title>
DESCRIPTION TAG
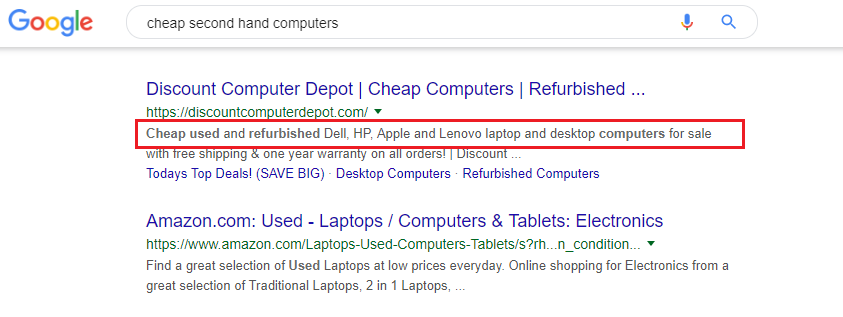
How the Title tag displays in Google
Think of your description tag as the copy for an ad. You have 155 characters (including spaces) in which to craft an informative, compelling description. Try to use your keyword at least once in the Description, as close to the start as possible. For a product website, you might consider including the vital statistics about each product in the Description tag. E.g. Brand names, model numbers, colors, etc.
Note, however, that you don’t actually have to define a Description tag. Most search engines are capable of extracting what they need for the description from your site copy. Danny Dover, formerly of Moz, recommends defining a Description tag for the Home page, and leaving the rest blank and letting the search engines decide what to display (they’ll choose what content to pull from your page based on the search query).
I’m not convinced. If you leave the search engines to their own devices, there’s no guarantee they’ll choose a section that’s well written or even intended to be the “copy for an ad” as I’ve suggested the Description should be. I recommend defining the Description on all pages.
It’s not a good idea to use the same Description on every page. It’s supposed to be helpful and persuade searchers to click through to your page. If it’s generic enough to be suitable for every page, it’s not going to be particularly engaging, compelling or helpful.
HOW THE DESCRIPTION TAG SHOULD LOOK IN THE CODE
<meta name="DESCRIPTION" CONTENT="Cheap second hand computers for sale – Find a cheap second hand Dell computer for the kids. All computers come with Windows & Office installed & a 2 year warranty." />
ALT TAG
When vision-impaired people access your page, their screen reader describes pictures by reading aloud their Alt tags.
Because the search engines assume your pictures have something to do with your subject matter, they pay some attention to the Alt tag when indexing your page. Try to include your keyword at least once in your Alt text. But don’t overdo it, or you may be
penalized.
HOW THE ALT TAG SHOULD LOOK IN THE CODE
<img src="filename.gif" alt="Cheap second hand computer in use" title="Cheap second hand computer in use">
KEYWORDS TAG
A comma-separated list of keywords that are most relevant to the subject matter of the
page.
Stick to about 300 characters and don’t repeat your keywords over and over. You can, however, include variations of your keyword, such as “copy”, “copywriter”, “copywriters” and “copywriting.” You can also re-use a keyword so long as it’s part of a different phrase.
The Keywords tag isn’t visible to visitors of your website (unless they view the source). It’s really just a legacy from a time when the search engines used it as their sole means of identifying a site’s subject matter.y
HOW THE KEYWORDS TAG SHOULD LOOK IN THE CODE
<meta name="KEYWORDS" CONTENT="cheap second hand computers,reliable second hand computers" />
USE IMAGE CAPTIONS
No magic here. And nothing technical. Just another way to get your target keywords on the page. In addition to your image Alt tags, add a caption to your images, explaining their content. Because they’re outside the flow of the copy, they’re easy to optimize without impeding readability. You can even include links. In fact, you can even add images just for SEO, so long as they still add some value to your reader too.
STRUCTURE YOUR SITE AROUND KEYWORDS
Visitors and search engines, alike, prefer a structured site. As discussed on p.129, it’s good practice to structure your site around the keywords you want to target. This is generally called clustering’, ‘theming’ or ‘siloing’. The easiest way to explain clustering is to illustrate it:

Structure your site around your keywords – ‘Theming’
This approach:
- Makes your site more usable;
- Allows you to target many different keywords, site-wide, but still focus on a small handful per page;
- Allows you to target both broad keywords (up high, e.g. “pets”), and specific keywords (down low, e.g. “Persian cats”);
IMPORTANT: You must also consider your message, not just your keywords, when you structure your website. If you structure your website without thought to the content, you’ll end up trying to squeeze the copy into an inappropriate structure.
For more information on structuring pages around keywords, see ‘What if I want to target more than one keyword phrase?’.
ADD YOUR NAME, ADDRESS & PHONE NUMBER TO EVERY PAGE IF LOCAL CUSTOMERS ARE IMPORTANT TO YOU
When Google decides what businesses to display in its local results (see ‘Local search’), one of the things it considers is the phone number, address and name of the business.
If these elements feature prominently on your site, Google will deduce that they’re important to visitors, which is a signal that your site is one that services mostly local customers. And this will make it more likely to include your site in local search results.
OPTIMIZE YOUR INTERNAL LINK ARCHITECTURE
For search engine bots, text links are like doorways from page to page and site to site. This means websites are generally better indexed by search engines if their bots can traverse the entire site using text links. This is a typical text link in HTML:
<a href="http://www.example.com/product -catalog.html">Product Catalog</a>
But there’s more to it than that. Links from top level pages (like the ‘Home’ and ‘Products’ pages) carry more weight than links from lower level pages (e.g. the ‘10 reasons why the ball bearings in our widget last longer’ page). The logic here is that if you link to a page from a top level page, you obviously want a lot of your visitors to see that link, so it must be key to your subject matter and business model.
Internal links also tell the search engines what pages are important. In other words, if you link to a page again and again and again, and you use meaningful anchor text, Google will assume that page is a core part of your subject matter, and index you accordingly.
What’s more, every time you link to a page, it’s passed a bit of PageRank. Link to it enough, and it will become one of your higher ranking pages, as it develops ‘link equity’.
So when you’re planning the structure of your site, if it doesn’t adversely impact the user experience:
Add a sitemap page (e.g. http://www.divinewrite.com.au/sitemap/ ) to your site, so that all pages are accessible via at least one text link. And consider adding an open format sitemap specifically for the search engines. (See ‘Create an open format / Google sitemap’)
Keep your page hierarchy as flat as possible. Some pages in your site will attract many backlinks, and some will attract very few. By keeping your page hierarchy flat, you ensure that all pages are within just a few internal links of each other, and that as much internal link equity as possible flows through to the pages that attract few backlinks. Most SEOs recommend a maximum of four levels.
Link to your most important pages often (with simple text links). This builds the ‘link equity’ of those pages.
Limit links to fewer than 100 per page. Remember the visitor; use leading usability expert, Jakob Nielsen’s advice:
“…include links to other resources that are directly relevant to the current location. Don’t bury the user in links to all site areas or to pages that are unrelated to their current location.”
Place your links prominently on each page. The search engines pay more attention to links toward the top of the page, and visitors are OK with prominent links too. Jakob Nielsen cites a study by Vora et al. that suggests users performed 26% faster when the anchors were part of the main text.
Consider adding a nofollow to links that point to less important pages, so that the search engines don’t visit those pages. This increases the relative link equity of all your other pages. A nofollow looks like this:
<a href="page1.htm" rel="nofollow">go to page 1</a>
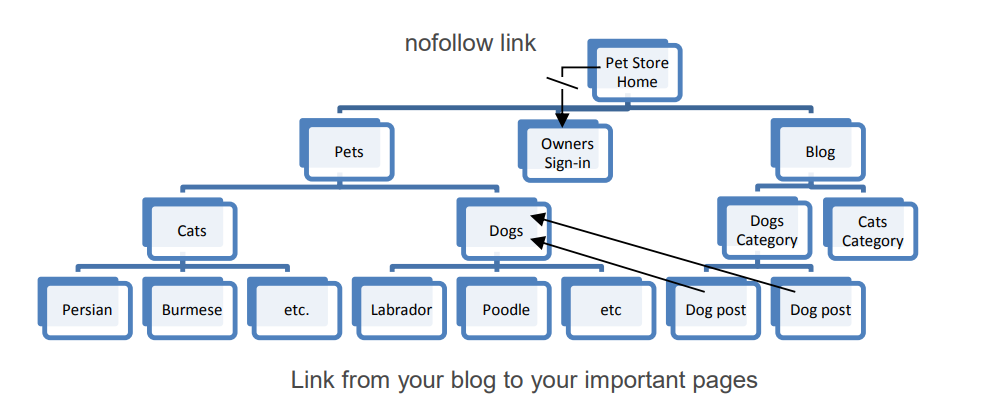
Visualizing internal link architecture
TIP: If you sign up to Google Webmaster Tools, you can use one of its features to see if Googlebot (the Google crawler) can find your internal links. (‘Links > Pages with internal links’).
ADD TITLES TO INTERNAL LINKS
HTML links can include a Title, which becomes a tooltip when a visitor hovers their mouse over the link. They’re also read out by screen readers for the vision-impaired people. Because this aids accessibility and helps reduce visitor disorientation, and because it’s indicative of the content of the destination page, search engines crawl it and it plays a part in how they index the page (albeit a small part).
Link titles look like this:
<a href="http://www.divinewrite.com/portfolio.htm" title="Copywriting portfolio for Divine Write Copywriting">Portfolio</a>
USE STRUCTURED DATA
If you run one of the following types of sites, you should be using structured data (and Google wants you to):
- an e-commerce website (e.g. you sell electronics or fashion products)
- a restaurant or café website
- a website that promotes events (concerts, theatre productions, festivals, etc.)
- a cinema website
- a recipes website
- a reviews website
- a website that sells software
- a website for any business that relies heavily on customer reviews or client testimonials
WHAT IS STRUCTURED DATA?
‘Structured data’ is a special sort of instruction for the search engines in the HTML of your site. Basically a label or annotation that the search engines can clearly understand, and which gives you more control over how your content is displayed in search results.
For example…
If you write about electronics devices, and you allow your readers to review and rate products, you should provide the average reader rating for each product, so Google can display this information directly within its search results.
You’d do this by adding some special code to each recipe that tells Google “THIS IS THE AVERAGE CUSTOMER RATING”. You don’t say it in words like that, obviously. It’s all done with HTML. When Google reads your web page and sees that code, it immediately knows, without a shadow of a doubt, that it’s reading the average customer rating.
Here’s an example of some structured data for average (or aggregate) customer rating, along with Google’s treatment of it (it displays a ‘rich snippet’).
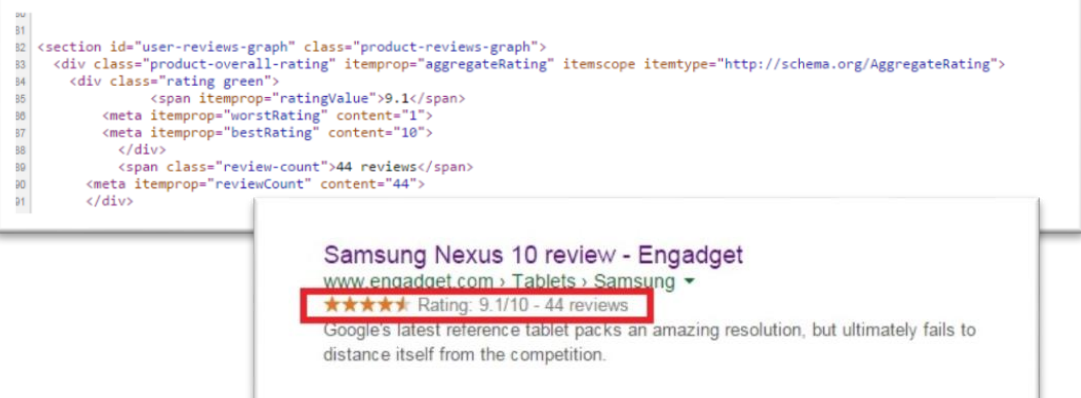
Example of structured data
Structured data also increases the likelihood that Google will display your content as an authoritative answer to searches like, “how old is white house?”. Like this…
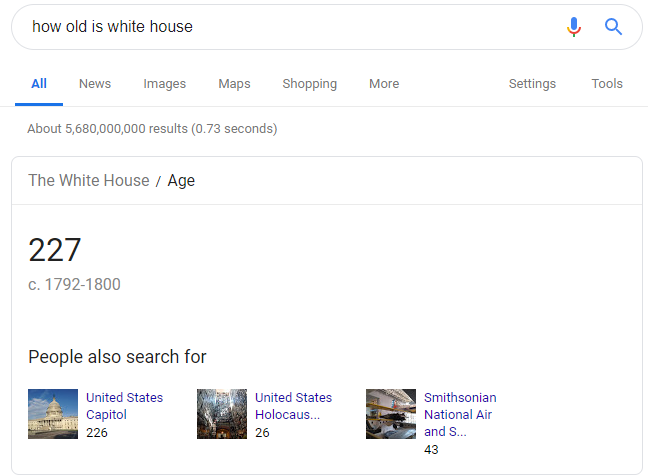
Structured data and authority
You have to be a pretty authoritative site to get this sort of treatment though.
WHAT CONTENT SHOULD YOU ADD STRUCTURED DATA MARKUP FOR?
Google can display rich snippets for the following data types (and more), so if your site contains any of these things, you should definitely be using structured data markup:
- Product image, reviews, average rating, price and availability.
- Recipe image, reviews, ratings, nutritional information, cook time, prep time and total time.
- Review text, reviewer name, review date and reviewer rating.
- Event name, location, date and price.
- Software app name, average rating, operating system and category.
For more information on how to use and format structured data, see Google’s instructions on rich snippets or schema.org.
LINK TO RELATED SITES
Linking to external sites may seem ill-advised, because you’re sending away visitors. But it’s actually a very good idea. Assuming you link to relevant, helpful sites, your visitors will thank you for it, and will be more likely to bookmark your site and come back repeatedly.
This is particularly true of outbound links to ‘hub sites’ – the really, REALLY big ones in your field. If you link out to them, the search engines figure you’re adding value to your visitors, and this is argued to count in your favor.
Here’s what Matt Cutts (the ‘Google Insider’) has to say on external links:
“…if the user is happy, they are more likely to come back or bookmark your site or tell their friends about it. And so, if you try to hoard those users, they often somehow subconsciously sense it, and they are less likely to come back or tell their friends about it.”
Translation? Outbound links can impact your ranking favorably. (When discussing ranking factors, Matt usually talks in terms of visitor experience.)
CHECK FOR BROKEN LINKS
Broken links are bad for visitors because they convey the impression that your site is not well maintained, and they‘re bad for SEO because they can stop the search engine bots from crawling all your pages.
Note that Google specifically advises webmasters to check for broken links. It’s entirely possible that Google views broken links as a sign that your site is in poor repair, just as human visitors do, and that the existence of broken links may impact your ranking simply because Google wants well maintained sites at the top of its SERPs.
You can use a tool called Xenu to find broken links. It’s simple to use and the reports are self-explanatory.
ADD A SITEMAP PAGE
Create a sitemap page containing a list of text links to every page in your site. Link to your sitemap from the footer of every other page. (Your sitemap page is not the same thing as an open format / Google sitemap.)
If your site has a lot of pages, it may take you some time to create your sitemap page. Although I’ve never tried any, there are a few tools out there that claim to automate the process. Like Smart IT Consulting’s HTML Site Map Script.
TIP: Because site maps are used by both search engine bots and human visitors, you need to make it user-friendly. Try using bolding and indenting to represent your site hierarchy. See http://www.divinewrite.com.au/sitemap/ for an example.
If your site has any pages that are referenced by more than one URL (e.g. pages with URLs that track visitor information – those with affiliateID, trackingID, etc.), use the cleanest, shortest, most user-friendly URL on the sitemap page. This will help the search engines choose the correct URL to display in their SERPs. See ‘Avoid duplicate content’ for more information.
CREATE AN OPEN FORMAT / GOOGLE SITEMAP
A Google sitemap is an optional XML file that lists all of the public pages on your site, and a whole bunch of data for each, including when it was last updated, how often you update it, and how important you consider it.
A Google sitemap won’t affect your ranking, but it may affect how quickly you appear in the SERPs, because Google may index your pages faster and more often. None of it’s guaranteed though.
To create a Google sitemap, download and run softPLUS GSiteCrawler. It’s a very easy program to use; all you do is type your site’s URL and a couple of other simple details, and it does the rest. It’ll even upload the resultant XML file to your FTP site automatically! (It has to go in your site’s root directory.)
GSiteCrawler also handles self-hosted WordPress blogs and phpBB forums.
Once you’ve uploaded your Google sitemap, sign in to your Google Webmaster Tools account, and submit (or re-submit) it. Google will ask you to verify your ownership of the site by placing an HTML file with a particular name in the root directory, or by adding a line of code to one of your files.
TIP: To get best use out of a Google sitemap, you should really re-crawl your site and re upload the XML file each time you add a new page to your site. But GSiteCrawler has you covered there, too, as it allows you to schedule automatic crawls and updates. You’ll still have to manually re-submit the sitemap in Google Webmaster Tools, though.
USE PERMANENT 301 REDIRECTS FOR CHANGED URLS
If ever you change a page’s URL, you need to redirect the old URL to the new one. If you don’t, all old links will point to a page that no longer exists, including any search results. Visitors won’t be able to get through, and you won’t get any PageRank from backlinks.
Your web developer will know what you’re talking about when you instruct them to use 301 redirects. But just in case, here’s an instruction.
IMPORTANT: Be aware, however, that when you move a page to a new location, its PageRank can take a while to catch up with it. Google recommends maintaining the 301 redirect for as long as you have control of the original URL. (Just one more reason to avoid moving your pages!)
CREATE A CUSTOM 404 ERROR HANDLING PAGE
A 404 error handling page is some geek’s name for the page that displays when someone tries to reach a non-existent page on your site. Usually this happens when they click on a broken link, you’ve deleted or moved a page, or they just mistyped the URL.
Unfortunately, the standard 404 page – provided by your ISP – truly lives up to its geeky name! It usually looks something like this:

A standard ugly & very geeky 404 error handling page.
Not very friendly, is it? When confronted with this, the only thing a would-be visitor can do is click Back. And if the link that brought them here is on another site, that’s likely the last you’ll see of them. So creating a visitor-friendly, helpful 404 error handling page is a must.
Most of the issues surrounding 404 error handling pages pertain to conversion, not SEO. However, there are two that are search-related:
You have to find out from your web host how to report the 404 status to the search engines. In other words, how to tell the search engines that your 404 page is an error page, and shouldn’t be indexed or displayed in the SERPs.
Broken links are backlinks waiting to happen. To fix them, you have two choices: i) notify the webmaster in control of the incorrect link, and ask them to fix it; or ii) set up a 301 redirect for each, to redirect the incorrect link to the correct URL. Once you know how to do them, 301 redirects are a lot easier and faster, but they do put a slight strain on your web server.
For more information on setting up a custom 404 error handling page, see Google’s Custom 404 pages, Bruce Clay’s Improve SEO With a Custom 404 Page and Jeff Atwood’s Creating User Friendly 404 Pages.
CREATE A ROBOTS.TXT FILE
Use this file to tell the search engine bots what they can and cannot crawl and/or index. (You might, for instance, not want search bots to crawl and index your admin page, or your e-book.)
Visit The Web Robots Pages to learn how to create a robots.txt file, or create one ‘point ‘n click’ style with Google Webmaster Tools. When you’re done, put it in the root directory on your web server (e.g. www.yourdomain.com/robots.txt.)
You can check that your robots.txt file is working properly using the Analyze robots.txt tool in Google Webmaster Tools.
Oh, and make sure you keep it up to date so you don’t accidentally block any bots.
If, for some reason, you don’t have access to your site’s root directory, you can add a Robots meta tag to the header section of every page in your site that you don’t want crawled and/or indexed. Note, however, that not all bots will honor the meta tag, so it’s not as reliable as the robots.txt file.
The Robots meta tags are as follows:
<meta name="ROBOTS" CONTENT="ALL" />tells the bots to crawl and index your entire site<meta name="ROBOTS" CONTENT="NONE" />tells the bots not to index anything.<meta name="ROBOTS" CONTENT="NOINDEX,FOLLOW" />says don’t index this particular page, but follow its links to other pages (e.g. for use on secure or private pages).<meta name="ROBOTS" CONTENT="INDEX,NOFOLLOW" />says to index the page but not follow its links.
Here’s an examples of what the robots tag looks like in practice.
<html>
<head>
<title>Cheap second hand computers admin page</title>
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
</head>
USE SUBFOLDERS OR SUBDOMAINS – THEY’RE BOTH OK
Over the years, there’s been a lot of talk about whether low-level content should be stored in subfolders or sub-domains. The truth is, it really doesn’t make any difference to your SEO. Just choose the option that suits your technical capabilities (and any other requirements).
CONSIDER MAKING DYNAMIC URLS STATIC
When a site’s content is called from a database, its URLs are normally generated on the fly. You can tell if a URL is dynamic because it’ll have characters like, “?”, “=” and “&” in it. This is typical of sites that utilize a Content Management System (CMS) –including blogs. E.g.:
http://www.mysite.com/main.php?category=books&subject=biography
Static URLs, on the other hand, are tied to their content, and are generally a combination of the page’s filename and directory location. E.g.:
http://www.divinewrite.com.au/portfolio/copywriting/
The three main problems with dynamic URLs are:
- They can lead to duplicate content issues – See ‘Avoid duplicate content issues in your blog’ on p.81 and ‘Avoid duplicate content’ on p.66 for more information on duplicate content.
- Search engines can have trouble reading them properly – Google can now read and index them very effectively. (There are, after all, millions of sites with dynamic URLs in Google’s SERPs.) But that’s not to say that they can read and index them as effectively as they can static URLs. In fact, Google’s Search Quality Team says,
“…the decision to use database driven websites does not imply a significant disadvantage in terms of indexing and ranking.”
The important words here are, “significant disadvantage.” What’s more, not all search engines crawl dynamic URLs as effectively as Google.
- They reduce click-thrus from search engine results, they’re harder to remember, share and write down, they’re easily clipped, they’re often not keyword rich, and they often don’t give readers any clue about what to expect at the destination site.
These issues can be overcome by rewriting your dynamic URLs in such a way that they become static. For example, the following dynamic URL:
http://www.mysite.com/main.php?category=books&subject=biography
Could be rewritten to become the following static URL:
http://www.mysite.com/pagebooks-biography.htm
Unfortunately, static URL rewriting is not without risks of its own. If done incorrectly, it can cause Google problems crawling and indexing your pages. Google now explicitly advocates dynamic URLs:
“Providing search engines with dynamic URLs should be favored over hiding parameters to make them look static.”
Of course, it’s important to remember that Google’s a public company, answerable to shareholders. It’s ability to crawl and index dynamic URLs better than its competitors is a significant competitive advantage, if leveraged. Who’s to say that the above advice isn’t merely an attempt to leverage that ability?
My advice? If you’re using a CMS that doesn’t offer trustworthy dynamic URL rewriting, stick with dynamic URLs. If, however, your CMS rewrites dynamic URLs very well (e.g. WordPress or any CMS using mod_rewrite), then consider rewriting to static URLs – if it will help your customers and aid your promotions significantly. Rewriting dynamic URLs isn’t likely to have a huge impact on your rankings, so I would avoid it unless I was sure it wasn’t going to cause problems.
That concludes what you should do if you want to develop your website right. Now, let’s move on to what you should avoid doing or not do in the first place when developing your website.